Some Neural Networks Math
From Chapter 1 of Michael Nielsen’s “Neural Networks and Deep Learning”
Goal
Deepen mathemamatical understanding of fundamentals of a neural network. I have worked on a neural network project before (see my older posts), but it was done in one week, and I accepted a lot of abstractions. This post was going to include an implementation of a neural network to recognize hand digits, but after a few days of failing to reach a reasonably good accuracy, I moved on and am going to focus on another project that I started a while ago. Also, this is poorly structured, and I could find a better markdown extension for mathematical notations instead of photos of my work, but this is mainly for me, so it’s not problem right now. ‘Till next time NNs and machine learning…We shall meet again after I have developed my b*****n implementation and grinded out more web development stuff.
Perceptrons vs. Sigmoid Neurons
Perceptrons take several binary inputs, x1, x2 …, xN and produces a single binary output. The weights are real numbers expressing importance of respective inputs to the outputs. The output is 0 or 1 determined by whether the weighted sum is less than or greater than a threshold value. Instead of a threshold value, we can use a bias to measure how easy it is to get the perceptrons to output a 1. This model is not complex enough or general enough to be used for more complex tasks. They are only able to learn linear relationships (the weighted sums are basically just linear combinations), the activation function is just a step fuction (0 or 1); this also means that perceptrons can’t output probabilities which is important for classification tasks such as handwritten digit recognition. Additionally, a small change in the weights or bias of a perceptron-based neural network can lead to major changes in the outputs. Alternatively, sigmoid neurons allow for small changes in their weights and biases to only cause small changes in the outputs because inputs in a sigmoid model can take on values between 0 and 1.
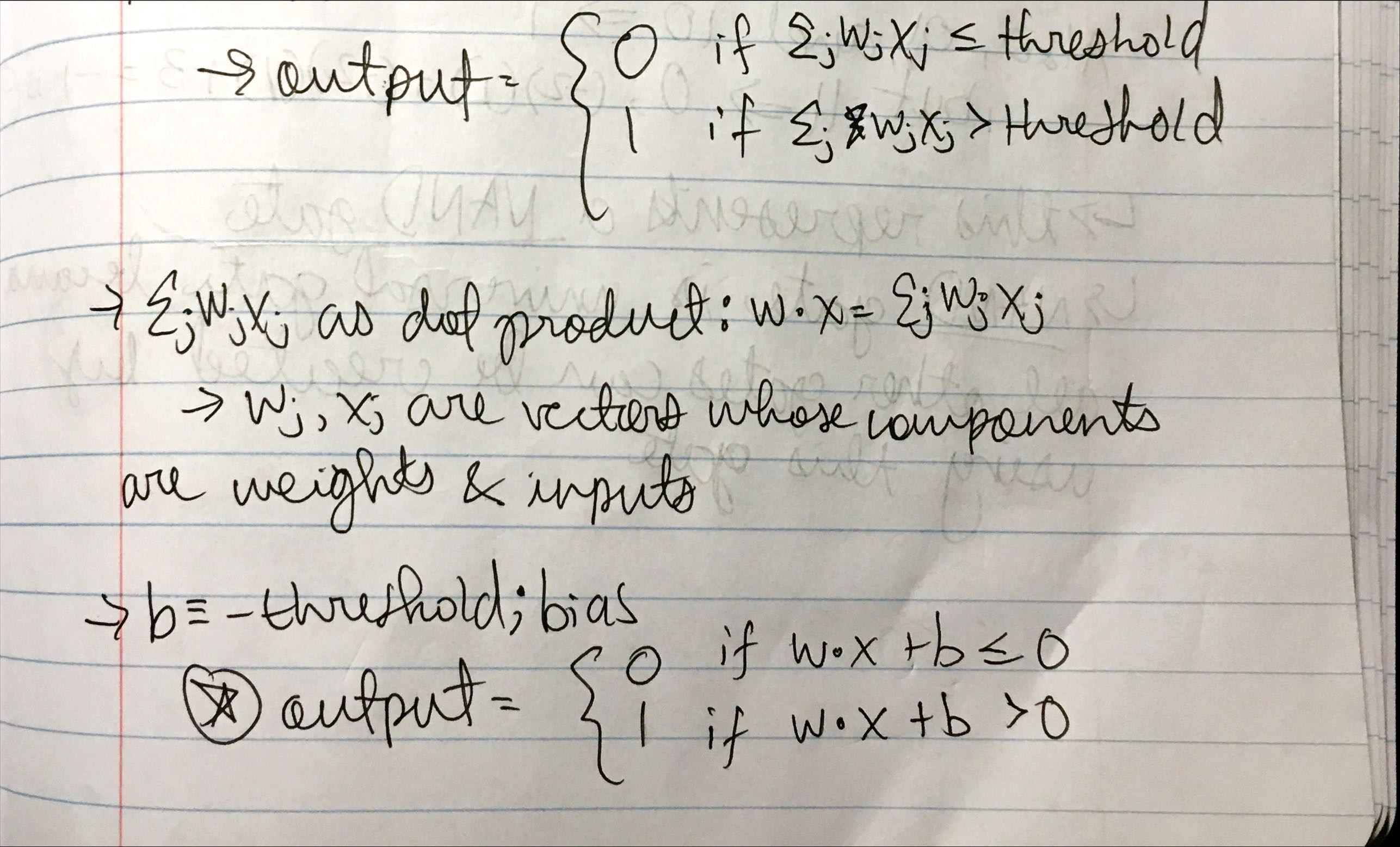
%202.jpeg)
%203.jpeg)
%204.jpeg)
Problems and Proofs
- Take all the weights and biases in a network of perceptrons, multiply them by a positive constant, c > 0. Show behavior of network does not change.
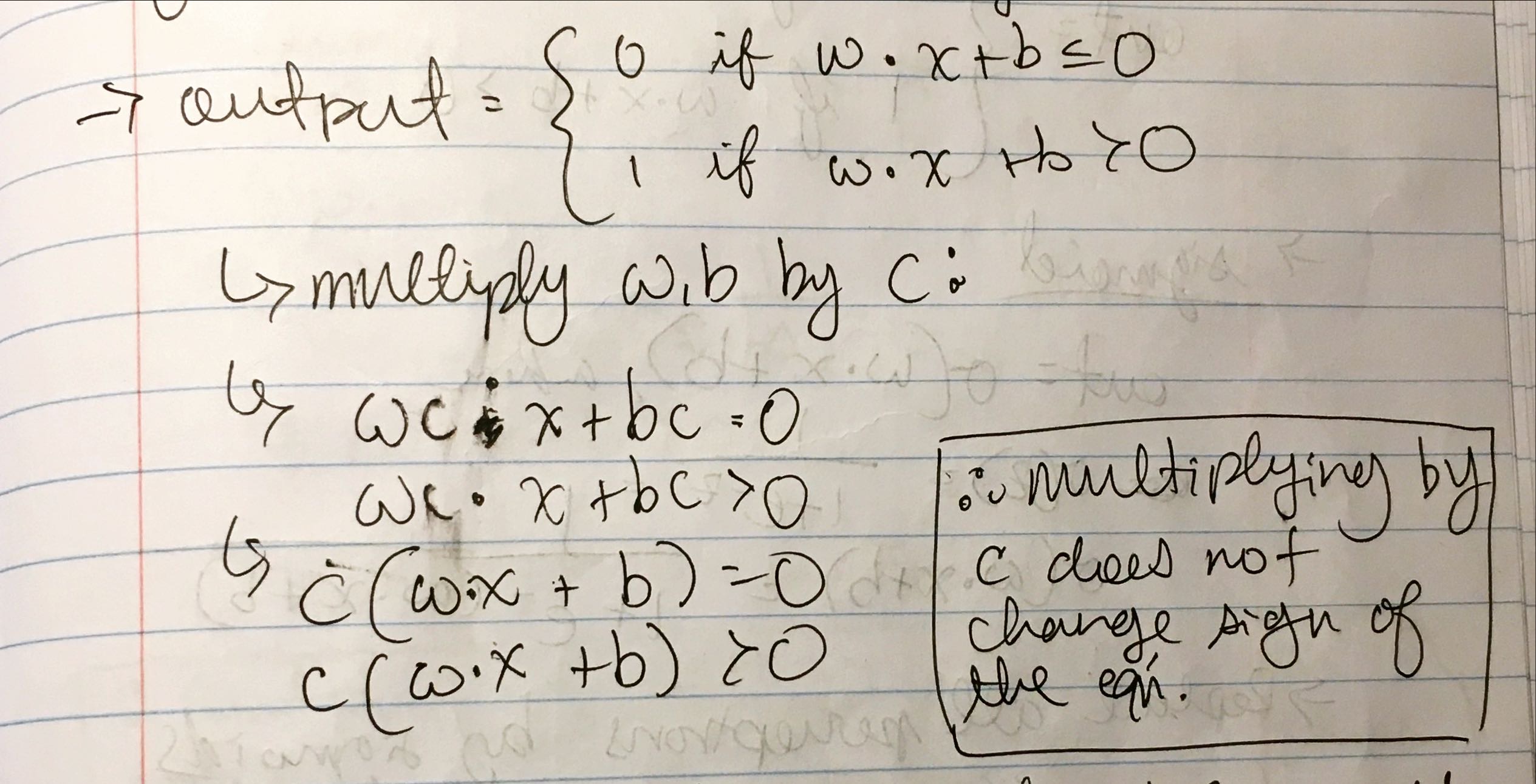
- Suppose a network of perceptrons and overall input to the network has been chosen. Weights and biases are such that wx + b != 0, for the input x to any particular perceptron. Now replace all perceptrons in the network by sigmood neurons, and multiply the weights and biases by a positive constant c > 0. Show that as c -> infinity the behavior of this network of sigmoid neurons is exactly the same as the network of perceptrons. How can this fail when wx + b = 0 for any one of the perceptrons?
%202.jpeg)
Simple Architecture for Classifying Handwritten Digits
We split the problem into two subproblems. First is breaking an image containing many digits into a sequence of separate images. The second is classifying each individual digit. Let’s focus on the second subproblem. For each handwritten digit iamge, the input layer consits of 784 neurons (28 x 28 image), one hidden layer contians 15 neurons (arbitrary), and the output layer contains 10 neurons (0 to 9 for each digit). We can describe each input neuron’s (pixel) value as a greyscale value from 0.0 (white) to 1.0 (black).

Exercise
Determine the bitwise representation of a digit by adding an extra layer to the three-layer neural network. The extra layer converts the output from the previous layer into a binary representation. Find a set of weights and biases for the new output layer. Assume old output layer and has a correct activation neuron of >= 0.99 and incorrect outputs have <= 0.01.
%202.jpeg)
%203.jpeg)
%204.jpeg)
Learning With Gradient Descent
The goal is to find an algorithm that lets us find the correct weights and biases, so our output from the network approximates y(x) for all training inputs x. The difference between the actual output (digit) and the value our network spits out at any training instance is described by a cost function.
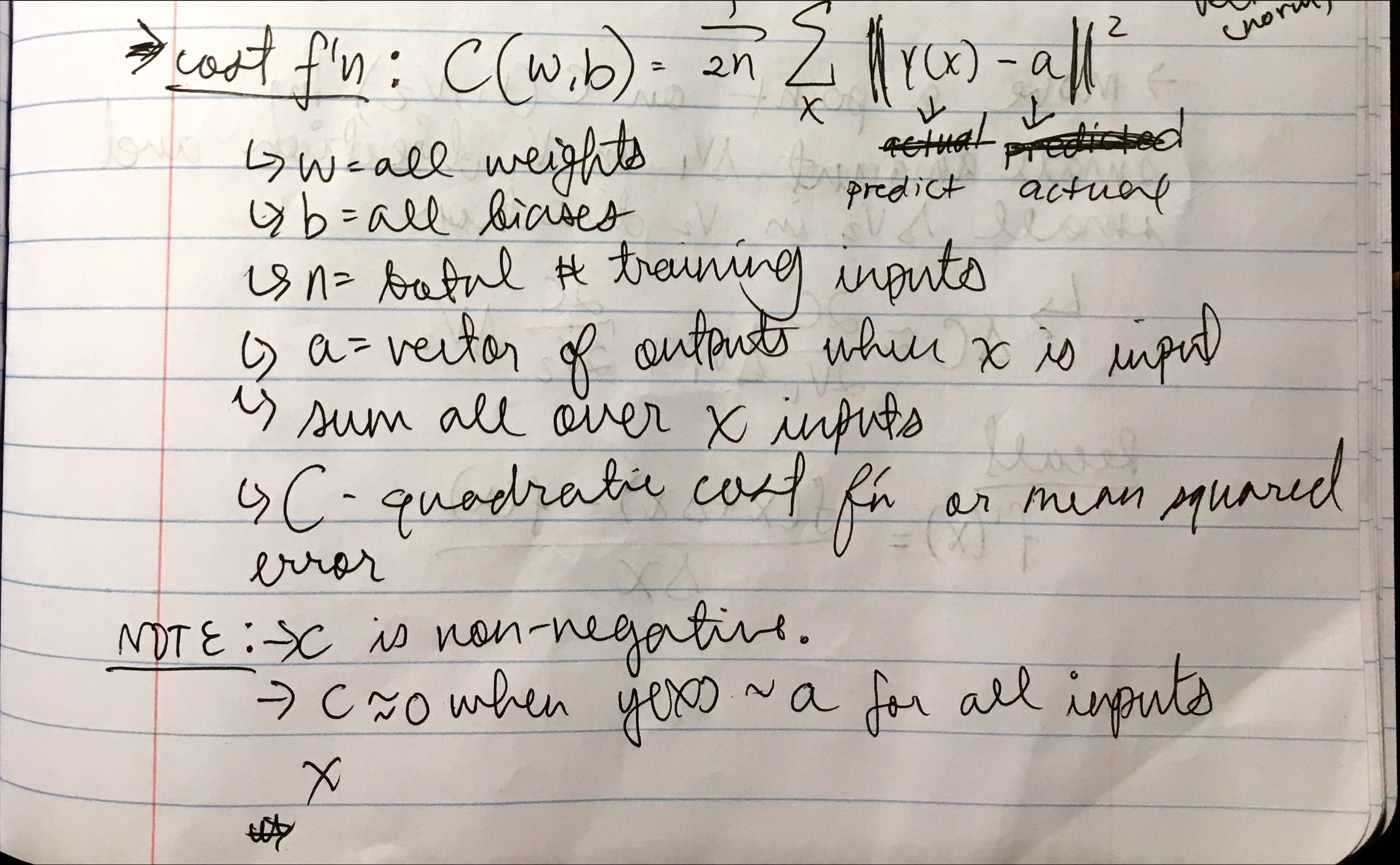
To minimize the cost function, we use an algorithm called gradient descent. We want to move a point on C(V1, V2) by a small amount dV1 in V1 direction and small dV2 in V2 direction until we get to a minimum.
%203.jpeg)
Exercise
 For this proof, we will use the Cauchy-Schwarz Inequality.
For this proof, we will use the Cauchy-Schwarz Inequality.
%205.jpeg)
What happens when C is a function of just one variable?
%206.jpeg)
That was a lot. You probably didn’t read more than a few sentences. Good for you, because this isn’t intended to make any sense to anyone else but me. This is my blog where I post thoughts, things I learn, projects, etc. Hope you have a lovely day.